
Multi-Modeling and Evolution in Software Ecosystems
Motivation
In software ecosystems (SECOs) internal and external developers compose customer solutions based on common technological platforms. The software systems providing the technical basis of a SECO are created by different teams and communities. This poses significant challenges for development and evolution. Solutions exist in a growing number of versions and variants. Upgrading a system or parts of it at reasonable costs can become almost impossible as both the original system and the deployed system have evolved independently since the original deployment. Further, developers face high complexity as systems use multiple programming languages need to support a high degree of variability to customize them to the customer-specific requirements. As evolution is the rule and not the exception in SECOs, understanding the types and mechanisms of changes plays an important role. Another important issue arising in SECO development and evolution is merge and change support that addresses the diversity of the systems.
Approach
Together with our industry partner Keba AG we are developing methods and tools supporting distributed development and evolution in industrial SECOs. In an initial exploratory case study we identified key challenges for SECO development: managing and dealing with the different variants and versions in the software ecosystems; assessing the effect of changes in the core platform to existing variants and versions; providing support addressing the different types and skills of developers in the SECO; as well as increasing the knowledge about commonalities and variability of existing solutions.
We approach these challenges by developing an environment supporting feature-oriented and role-specific views and by providing support for system evolution. Feature-oriented views foster the separation of concerns and help in locating relevant artifacts when making changes. Role-specific views are useful to distinguish features maintained by product managers and technical features managed in the release plans of platform teams. Our approach is based on configuration-aware static code analysis techniques which are capable to cross language boundaries.
Results
 Exploratory case studies. We conducted an exploratory case study in the industrial automation domain with the goal to identify key characteristics, research issues, and evolution challenges in industrial SECOs.
Exploratory case studies. We conducted an exploratory case study in the industrial automation domain with the goal to identify key characteristics, research issues, and evolution challenges in industrial SECOs.
Lettner, Daniela; Angerer, Florian; Prähofer, Herbert; Grünbacher, Paul, “A Case Study on Software Ecosystem Characteristics in Industrial Automation Software“, In: Proceedings Int’l Conference on Software and Systems Process (ICSSP 2014), Nanjing, China, 2014.
Lettner, Daniela; Angerer, Florian; Grünbacher, Paul; Prähofer, Herbert, “Software Evolution in an Industrial Automation Ecosystem: An Exploratory Study“, In: Proceedings Int’l Euromicro Conference on Software Engineering and Advanced Applications (SEAA 2014), Verona, Italy, 2014.
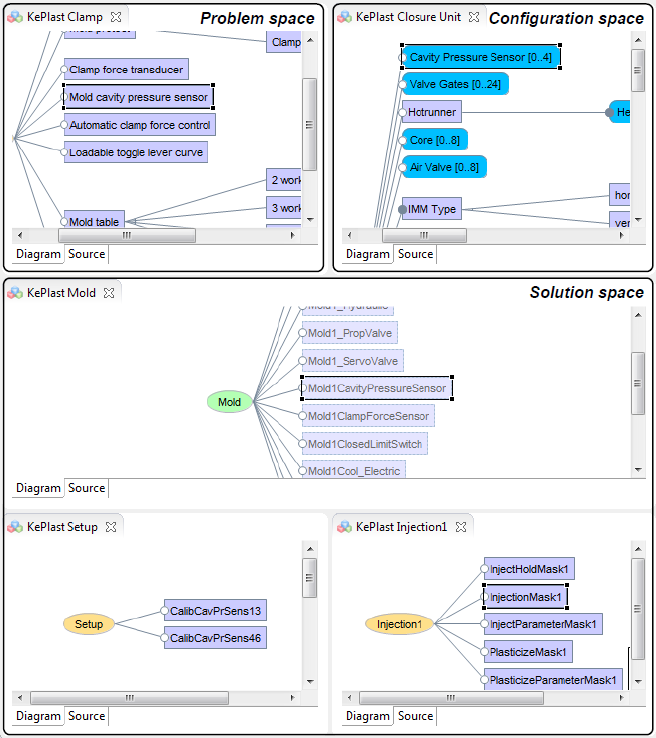 Multi-purpose, multi-level feature modeling of large-scale industrial software systems. Feature models are frequently used to capture the knowledge about configurable software systems and product lines. However, feature modeling of large-scale systems is challenging as models are needed for diverse purposes. For instance, feature models can be used to reflect the perspectives of product management, technical solution architecture, or product configuration. Furthermore, models are required at different levels of granularity. Although numerous approaches and tools are available, it remains hard to define the purpose, scope, and granularity of feature models. We report results and experiences of an exploratory case study on developing feature models for two large-scale industrial automation software systems and we present results on the characteristics and modularity of the feature models, including metrics about model dependencies. Based on the findings from the study, we developed FORCE, a modeling language, and tool environment that extends an existing feature modeling approach to support models for different purposes and at multiple levels, including mappings to the code base. We demonstrate the expressiveness and extensibility of our approach by applying it to the well-known Pick and Place Unit example and an injection molding subsystem of an industrial product line. We further show how our approach supports consistency between different feature models. Our results and experiences show that considering the purpose and level of features is useful for modeling large-scale systems and that modeling dependencies between feature models is essential for developing a system-wide perspective.
Multi-purpose, multi-level feature modeling of large-scale industrial software systems. Feature models are frequently used to capture the knowledge about configurable software systems and product lines. However, feature modeling of large-scale systems is challenging as models are needed for diverse purposes. For instance, feature models can be used to reflect the perspectives of product management, technical solution architecture, or product configuration. Furthermore, models are required at different levels of granularity. Although numerous approaches and tools are available, it remains hard to define the purpose, scope, and granularity of feature models. We report results and experiences of an exploratory case study on developing feature models for two large-scale industrial automation software systems and we present results on the characteristics and modularity of the feature models, including metrics about model dependencies. Based on the findings from the study, we developed FORCE, a modeling language, and tool environment that extends an existing feature modeling approach to support models for different purposes and at multiple levels, including mappings to the code base. We demonstrate the expressiveness and extensibility of our approach by applying it to the well-known Pick and Place Unit example and an injection molding subsystem of an industrial product line. We further show how our approach supports consistency between different feature models. Our results and experiences show that considering the purpose and level of features is useful for modeling large-scale systems and that modeling dependencies between feature models is essential for developing a system-wide perspective.
Lettner, Daniela; Eder, Klaus; Grünbacher, Paul; Prähofer, Herbert, “Feature Modeling of Two Large-scale Industrial Software Systems: Experiences and Lessons Learned“, In: Proceedings ACM/IEEE 18th Int’l Conference on Model Driven Engineering Languages and Systems, Ottawa, Canada, 2015.
Rabiser, Daniela; Prähofer, Herbert; Grünbacher, Paul; Petruzelka, Michael; Eder, Klaus; Angerer, Florian; Kromoser, Mario; Grimmer, Andreas, “Multi-Purpose, Multi-Level Feature Modeling of Large-Scale Industrial Software Systems“, In: Software and Systems Modeling, 2016.
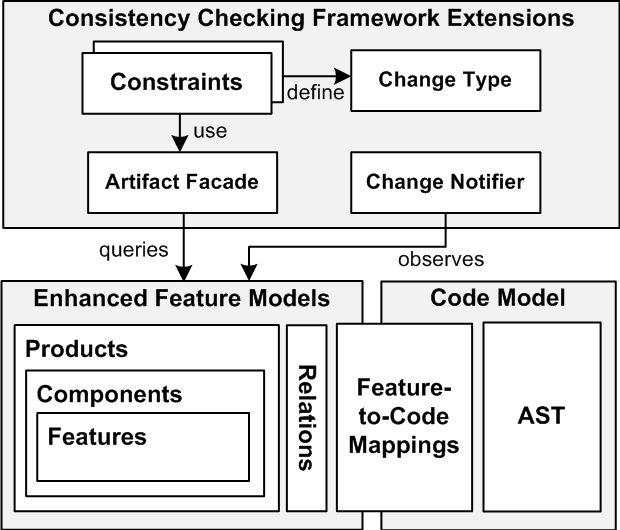 A Prototype-based Approach for Managing Clones in Clone-and-Own Product Lines. Feature models are commonly used in industrial contexts to guide and automate the derivation of product variants. However, in real-world product lines the derivation process goes beyond selecting and composing product features. Specifically, developers often perform clone-and-own reuse, i.e., they copy, modify, and extend existing code to provide the functionality required by customers. Clones are created at different levels of granularity, ranging from individual features to entire systems. Refactoring and reverse engineering approaches have been proposed for dealing with cloned product variants. However, managing clones has not been addressed in the context of feature models. For instance, if clones are created to address customer requirements in specific product variants, the connection to the original feature models is frequently lost. We thus present a modeling approach based on prototypes, i.e., prefabricated objects from which clones are created. Our approach allows to manage prototypes and their clones at the levels of products, components, and features. We use compliance levels to define the required level of consistency between prototypes and clones. We further adapt an existing consistency checking framework for detecting inconsistent clones when the product line evolves. Our approach uses feature-to-code mappings to determine the impact of changes on code elements.
A Prototype-based Approach for Managing Clones in Clone-and-Own Product Lines. Feature models are commonly used in industrial contexts to guide and automate the derivation of product variants. However, in real-world product lines the derivation process goes beyond selecting and composing product features. Specifically, developers often perform clone-and-own reuse, i.e., they copy, modify, and extend existing code to provide the functionality required by customers. Clones are created at different levels of granularity, ranging from individual features to entire systems. Refactoring and reverse engineering approaches have been proposed for dealing with cloned product variants. However, managing clones has not been addressed in the context of feature models. For instance, if clones are created to address customer requirements in specific product variants, the connection to the original feature models is frequently lost. We thus present a modeling approach based on prototypes, i.e., prefabricated objects from which clones are created. Our approach allows to manage prototypes and their clones at the levels of products, components, and features. We use compliance levels to define the required level of consistency between prototypes and clones. We further adapt an existing consistency checking framework for detecting inconsistent clones when the product line evolves. Our approach uses feature-to-code mappings to determine the impact of changes on code elements.
Rabiser, Daniela; Grünbacher, Paul; Prähofer, Herbert; Angerer, Florian, “A Prototype-based Approach for Managing Clones in Clone-and-Own Product Lines“, In: Proceedings 20th Int’l Software Product Line Conference (SPLC 2016), Beijing, China, pp. 35-44, 2016.
 Configuration-aware static program analysis of SECOs. In larger development and research effort we are working towards a configuration-aware static program analysis (CAPA) framework which forms a basis for supporting various development and evolution tasks in SECOs (e.g., diffing and merging, change impact analysis, or model-to-code consistency). In distinction to existing program analysis methods our analysis method considers code variability in SECOs. In a first work, we used the CAPA framework for determining code which is active or inactive in a concrete system configuration. We have been developing a tool that automatically identifies the relevant code for a concrete product variant and marks all code parts as inactive that cannot be executed in the current product configuration.
Configuration-aware static program analysis of SECOs. In larger development and research effort we are working towards a configuration-aware static program analysis (CAPA) framework which forms a basis for supporting various development and evolution tasks in SECOs (e.g., diffing and merging, change impact analysis, or model-to-code consistency). In distinction to existing program analysis methods our analysis method considers code variability in SECOs. In a first work, we used the CAPA framework for determining code which is active or inactive in a concrete system configuration. We have been developing a tool that automatically identifies the relevant code for a concrete product variant and marks all code parts as inactive that cannot be executed in the current product configuration.
Angerer, Florian; Prähofer, Herbert; Lettner, Daniela; Grimmer, Andreas; Grünbacher, Paul, “Identifying Inactive Code in Product Lines with Configuration-Aware System Dependence Graphs“, In: Proceedings 18th Int’l Software Product Line Conference (SPLC 2014), Florence, Italy, 2014.
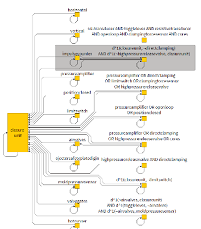 Recovering Feature-to-Code Mappings. Software engineering methods for analyzing and managing variable software systems rely on accurate feature-to-code mappings to relate high-level variability abstractions, such as features or decisions, to locations in the code where variability occurs. Due to the continuous and long-term evolution of many systems such mappings need to be extracted and updated automatically. However, current approaches have limitations regarding the analysis of highly-configurable systems that rely on different variability mechanisms. In this joint work with the ISSE institute we develop an approach exploiting the synergies between static program analysis and diffing techniques to reveal feature-to-code mappings for highly-configurable systems.
Recovering Feature-to-Code Mappings. Software engineering methods for analyzing and managing variable software systems rely on accurate feature-to-code mappings to relate high-level variability abstractions, such as features or decisions, to locations in the code where variability occurs. Due to the continuous and long-term evolution of many systems such mappings need to be extracted and updated automatically. However, current approaches have limitations regarding the analysis of highly-configurable systems that rely on different variability mechanisms. In this joint work with the ISSE institute we develop an approach exploiting the synergies between static program analysis and diffing techniques to reveal feature-to-code mappings for highly-configurable systems.
Linsbauer, Lukas; Angerer, Florian; Grünbacher, Paul; Lettner, Daniela; Prähofer, Herbert; Lopez-Herrejon, Roberto; Egyed, Alexander, “Recovering Feature-to-Code Mappings in Mixed-Variability Software Systems“, In: Proceedings of the 30th Int’l Conference on Software Maintenance and Evolution, 2014.
 Configuration-Aware Change Impact Analysis. Change impact analysis (CIA) is an important technique in software maintenance as it allows identification of the potential consequences of a change, or the estimation of what needs to be modified to accomplish a change. This work shows how to improve support for CIA in variable software systems and product lines. In distinction to conventional CIA approaches, the inter-procedural and configuration-aware CIA approach allows considering configuration of systems and in this way improve analysis precision. The benefits of the approach are demonstrated by two use cases: (i) in developing a product line, software engineers are supported by automatically determining the set of possibly impacted products when changing source code of a product family; (ii) in application development, software engineers are supported as they need not consider the whole product line when making changes and extension for a specific product. Furthermore, our work exploits the modularity of large-scale systems to first perform program analysis for individual modules, and later compose the pre-computed analysis results. This is particularly useful in the context of product lines, when product variants are derived by composing modules depending on specific customer requirements. Finally, we compared our variability-oblivious approach with a lifted strategy proposed in related work. The study compared the two tools regarding performance and precision based on five open source software product lines (SPLs). The results show that the delayed strategy is significantly faster for all SPLs with slightly lower precision.
Configuration-Aware Change Impact Analysis. Change impact analysis (CIA) is an important technique in software maintenance as it allows identification of the potential consequences of a change, or the estimation of what needs to be modified to accomplish a change. This work shows how to improve support for CIA in variable software systems and product lines. In distinction to conventional CIA approaches, the inter-procedural and configuration-aware CIA approach allows considering configuration of systems and in this way improve analysis precision. The benefits of the approach are demonstrated by two use cases: (i) in developing a product line, software engineers are supported by automatically determining the set of possibly impacted products when changing source code of a product family; (ii) in application development, software engineers are supported as they need not consider the whole product line when making changes and extension for a specific product. Furthermore, our work exploits the modularity of large-scale systems to first perform program analysis for individual modules, and later compose the pre-computed analysis results. This is particularly useful in the context of product lines, when product variants are derived by composing modules depending on specific customer requirements. Finally, we compared our variability-oblivious approach with a lifted strategy proposed in related work. The study compared the two tools regarding performance and precision based on five open source software product lines (SPLs). The results show that the delayed strategy is significantly faster for all SPLs with slightly lower precision.
Angerer, Florian; Grimmer, Andreas; Prähofer, Herbert; Grünbacher, Paul, “Configuration-Aware Change Impact Analysis, In: Proceedings of the 30th IEEE/ACM Int’l Conference on Automated Software Engineering (ASE 2015), Lincoln, Nebraska (USA).”
Angerer, Florian; Prähofer, Herbert; Grünbacher, Paul, “Modular Change Impact Analysis for Configurable Software”, In: Proceedings of the 32nd IEEE Int’l Conference on Software Maintenance and Evolution (ICSME 2016), Raleigh, North Carolina (USA).
Angerer, Florian; Grünbacher, Paul; Prähofer, Herbert; Linsbauer, Lukas, “An Experiment Comparing Lifted and Delayed Variability-Aware Program Analysis”, In: 33rd IEEE International Conference on Software Maintenance and Evolution, IEEE, Shanghai, China, 2017.”
 Exploring and visualizing program dependencies. The conditional system dependence graph (CSDG) which has been developed for supporting configuration-aware program analysis (see above) represents all control and data flow dependencies in a program plus variability information. Obviously, for industrial systems CSDGs can get huge. Thus, support is needed for developers for exploring and navigating the graphs. Therefore, we have developed an interactive tool, the so-classed SDG Browser, for selectively exploring, navigating and visualizing program dependencies. It allows to interactively explore the CSDG and supports several use cases, i.e., to show how statements can be executed, how variables can be set, or how a change impact occurs. The SDG Browser allows interactively and selectively exploring program dependencies, collapse and expanding dependencies, as well as zooming between different abstraction levels. Moreover, it uses the variability information for hiding dependencies, which are not feasible in the current configuration.
Exploring and visualizing program dependencies. The conditional system dependence graph (CSDG) which has been developed for supporting configuration-aware program analysis (see above) represents all control and data flow dependencies in a program plus variability information. Obviously, for industrial systems CSDGs can get huge. Thus, support is needed for developers for exploring and navigating the graphs. Therefore, we have developed an interactive tool, the so-classed SDG Browser, for selectively exploring, navigating and visualizing program dependencies. It allows to interactively explore the CSDG and supports several use cases, i.e., to show how statements can be executed, how variables can be set, or how a change impact occurs. The SDG Browser allows interactively and selectively exploring program dependencies, collapse and expanding dependencies, as well as zooming between different abstraction levels. Moreover, it uses the variability information for hiding dependencies, which are not feasible in the current configuration.
Prähofer, Herbert; Rabiser, Daniela; Angerer, Florian; Grünbacher, Paul; Feichtinger, Peter, “Feature-Oriented Development in Industrial Automation Software Ecosystems: Development Scenarios and Tool Support”, In: Proceedings 14th IEEE International Conference on Industrial Informatics (INDIN 2016), Poitiers, France, pp. 1218-1223, 2016.
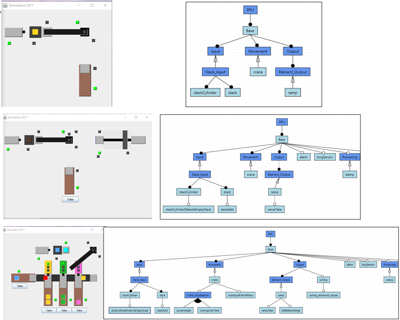 Feature-Oriented Evolution of Automation Software Systems in Industrial Software Ecosystems. In software ecosystems, individual products are often derived and adapted by adding new features or creating new versions of existing features to meet the customer-specific requirements. It is common industrial practice to first derive initial products from a product line, then adding and adapting features to satisfy individual customer requirements, possibly followed by merging back these changes into the original product line. Development teams typically use version control systems to track fine-grained, implementation-level changes to product lines and products. However, it is difficult to relate such low-level changes to features and their evolution in the SECO. The aim of our ongoing research is thus to support the development and evolution in SECOs at the level of features. Lifting the focus to features is essential, as they are widely used by product management, software architects, and developers in SECOs to communicate about systems and changes to systems. Our approach allows sharing new or updated features between individual developments in distributed product lines by transferring and exchanging them within the software ecosystem. This is for instance useful when a feature developed in an individual customer project becomes relevant for another market segment or when updates of features need to be transferred to related products in the ecosystem.
Feature-Oriented Evolution of Automation Software Systems in Industrial Software Ecosystems. In software ecosystems, individual products are often derived and adapted by adding new features or creating new versions of existing features to meet the customer-specific requirements. It is common industrial practice to first derive initial products from a product line, then adding and adapting features to satisfy individual customer requirements, possibly followed by merging back these changes into the original product line. Development teams typically use version control systems to track fine-grained, implementation-level changes to product lines and products. However, it is difficult to relate such low-level changes to features and their evolution in the SECO. The aim of our ongoing research is thus to support the development and evolution in SECOs at the level of features. Lifting the focus to features is essential, as they are widely used by product management, software architects, and developers in SECOs to communicate about systems and changes to systems. Our approach allows sharing new or updated features between individual developments in distributed product lines by transferring and exchanging them within the software ecosystem. This is for instance useful when a feature developed in an individual customer project becomes relevant for another market segment or when updates of features need to be transferred to related products in the ecosystem.
Hinterreiter, Daniel; Linsbauer, Lukas; Reisinger, Florian; Prähofer, Herbert; Grünbacher, Paul; Egyed, Alexander, “Feature-Oriented Evolution of Automation Software Systems in Industrial Software Ecosystems”, In: 23rd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA 2018), Torino, Italy, pp. 107-114, 2018.
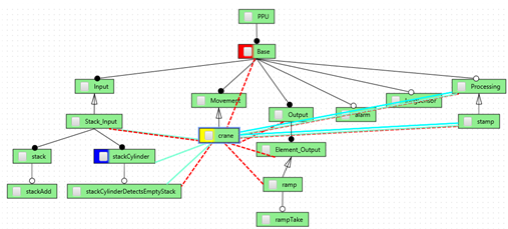 Lifting code-level dependencies to feature level. Feature models are widely used in software product lines and feature-oriented development approaches to define the commonalities and variability of software-intensive systems. Real-world product lines evolve continuously and engineers thus need to extend and adapt feature models to reflect the changes. However, engineers require deep knowledge about the domain and the implementation to avoid inconsistencies between a feature model and its implementation. Ensuring consistency is challenging due to the complexity of both feature-to-artifact mappings and implementation-level artifact dependencies. In an ongoing research endeavor we are working towards an approach for lifting code-level dependencies to the level of features. Specifically, the approach integrates feature modelling, feature-to-artifact mappings, and static analysis. Our global system dependency analysis (see above) is used to detect dependencies at the code level. Then, based on feature-to-artifact mappings these dependencies are lifted to the level of features, which can be used for checking if the constraints as represented in the feature model are consistent with the dependencies as detected at code level.
Lifting code-level dependencies to feature level. Feature models are widely used in software product lines and feature-oriented development approaches to define the commonalities and variability of software-intensive systems. Real-world product lines evolve continuously and engineers thus need to extend and adapt feature models to reflect the changes. However, engineers require deep knowledge about the domain and the implementation to avoid inconsistencies between a feature model and its implementation. Ensuring consistency is challenging due to the complexity of both feature-to-artifact mappings and implementation-level artifact dependencies. In an ongoing research endeavor we are working towards an approach for lifting code-level dependencies to the level of features. Specifically, the approach integrates feature modelling, feature-to-artifact mappings, and static analysis. Our global system dependency analysis (see above) is used to detect dependencies at the code level. Then, based on feature-to-artifact mappings these dependencies are lifted to the level of features, which can be used for checking if the constraints as represented in the feature model are consistent with the dependencies as detected at code level.
Hinterreiter, Daniel; Feichtinger, Kevin; Linsbauer, Lukas; Prähofer, Herbert; Grünbacher, Paul, “Supporting Feature Model Evolution by Lifting Code-Level Dependencies”, In: Proceedings of the 25th International Working Conference on Requirements Engineering: Foundation for Software Quality, Essen, Germany, 2019.
Team
Team Members
 |
Florian Angerer | Researcher |
 |
Thomas Böhm | Student Researcher |
 |
Kevin Feichtinger | Researcher |
 |
Peter Feichtinger | Student Researcher |
 |
Christoph Gerstberger | Student Researcher |
 |
Andreas Grimmer | Student Researcher |
 |
Michael Hansal | Student Researcher |
 |
Daniel Hinterreiter | Researcher |
 |
Mario Kromoser | Student Researcher |
 |
Lukas Linsbauer | Post-Doc |
 |
Martin Peché | Student Researcher |
 |
Herbert Prähofer | Senior Research Associate |
 |
Daniela Rabiser (Lettner) | Researcher |
 |
Florian Reisinger | Student Researcher |
 |
Paul Grünbacher | Head of Laboratory |